# Several people took an extra step and hard coded in the value
median(sd_data$MHI, na.rm = T)
mhi_median <- 57199
# You can streamline the code like this:
mhi_median <- median(sd_data$MHI, na.rm = T)
# We avoid hard coding variables because if you update the data set and the 'MHI'
# variable updates, then 'mhi_median' will automatically update.
# find the median value of median property value (MPV) and store the result in a variable called `mpv_median`
mpv_median <- median(sd_data$MPV, na.rm = T)
# find the median value of state revenue per pupil (SRPP) and store the result in a variable called `srpp_median`
srpp_median <- median(sd_data$SRPP, na.rm = T)
# find the median value of local revenue per pupil (LRPP) and store the result in a variable called `lrpp_median`
lrpp_median <- median(sd_data$LRPP, na.rm = T)Basic Data Analysis and Visualization in R
2023-06-13
The tidyverse is a powerful collection of R packages that work well together
The most popular packages in the R community are past of what is called the “tidyverse,” which includes packages like
ggplot2,tidyr,stringr,tibble, andpurrr.Tidyversepackages are built to work together. Everytidyversepackage contains functions that can manipulate or visualize data that lives in data frames.Most functions in the
tidyverserequire a data frame (R’s version of a table) as the first argument in each function. The functions can be “chained” together with other functions.We will explore the
tidyverseby looking at EdBuild’s FY2019 education data compiled from the F33 survey, SAIPE, EDGE, and CCD. Theedbuildrpackage provides access to clean district data on funding, student demographics, and wealth.

Step 1: Create a basic plot
Warning: Removed 8 rows containing missing values (`geom_point()`).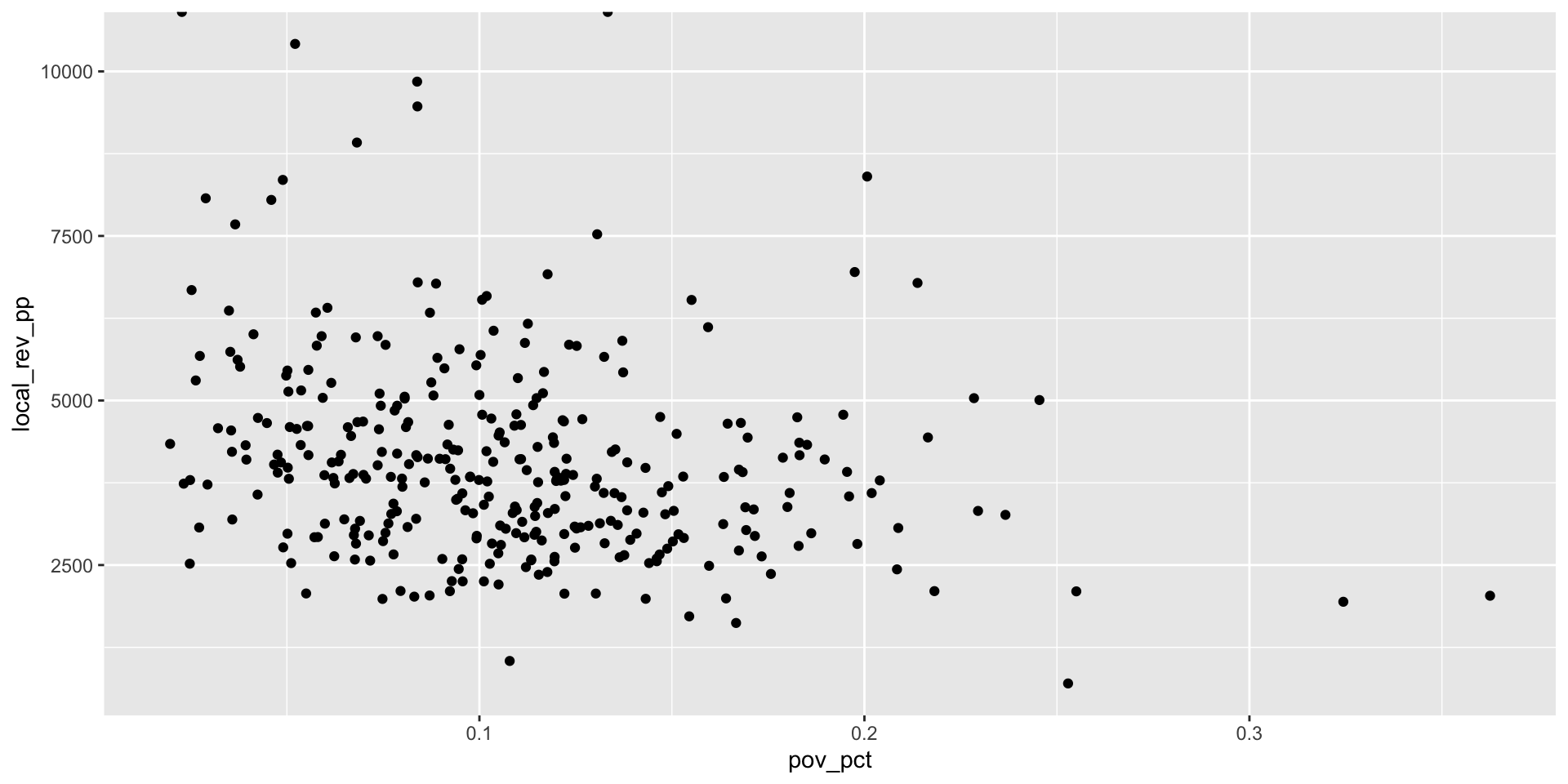
Step 3: Clean up formatting of chart elements (1/5)
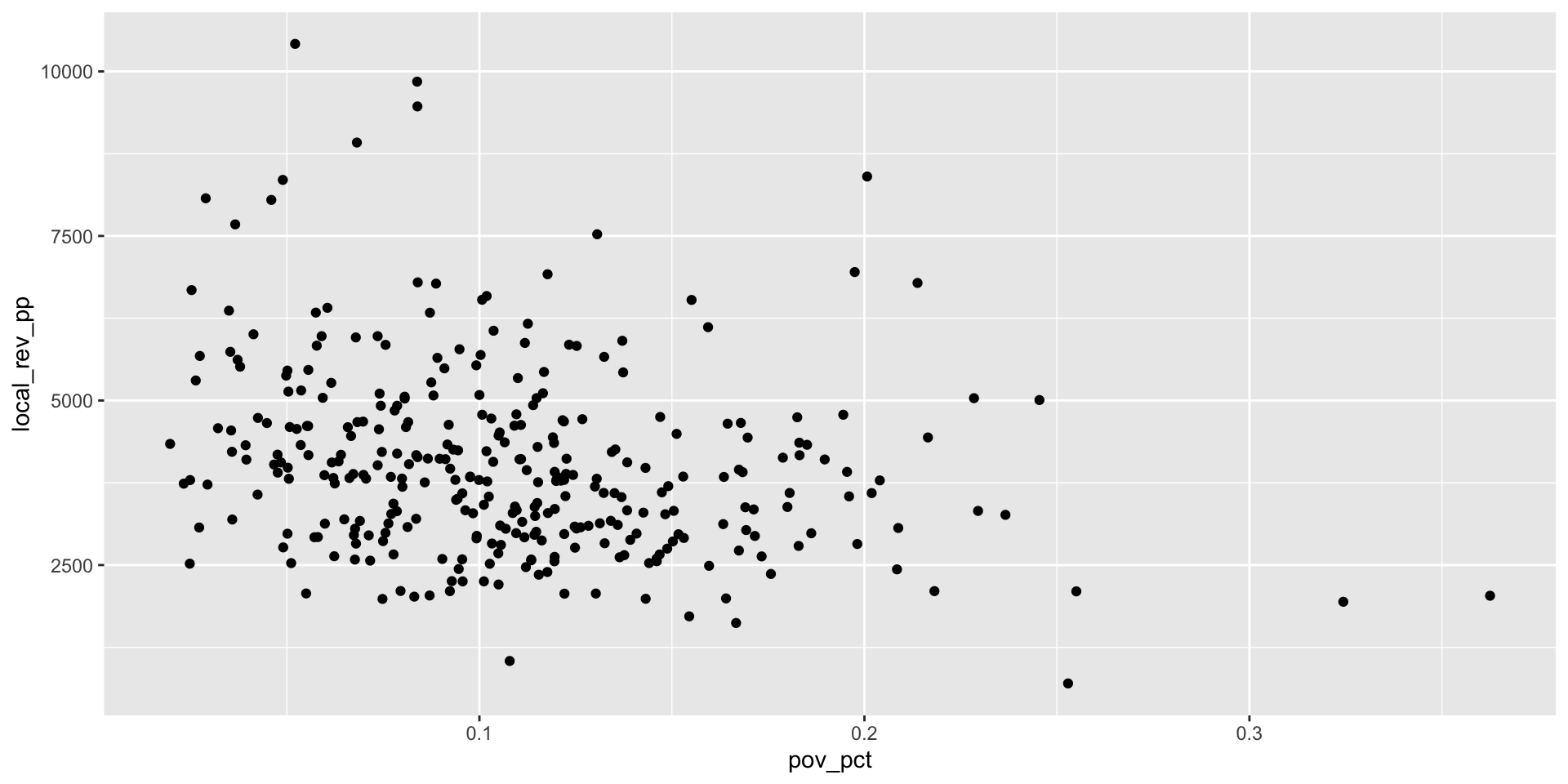
Step 3: Clean up formatting of chart elements (2/5)
We see some overlap in the points. Reducing the opacity of the points can be accomplished by setting the alpha parameter in geom_point() to a value less than 1. Setting it to .5 will make data points 50% translucent.
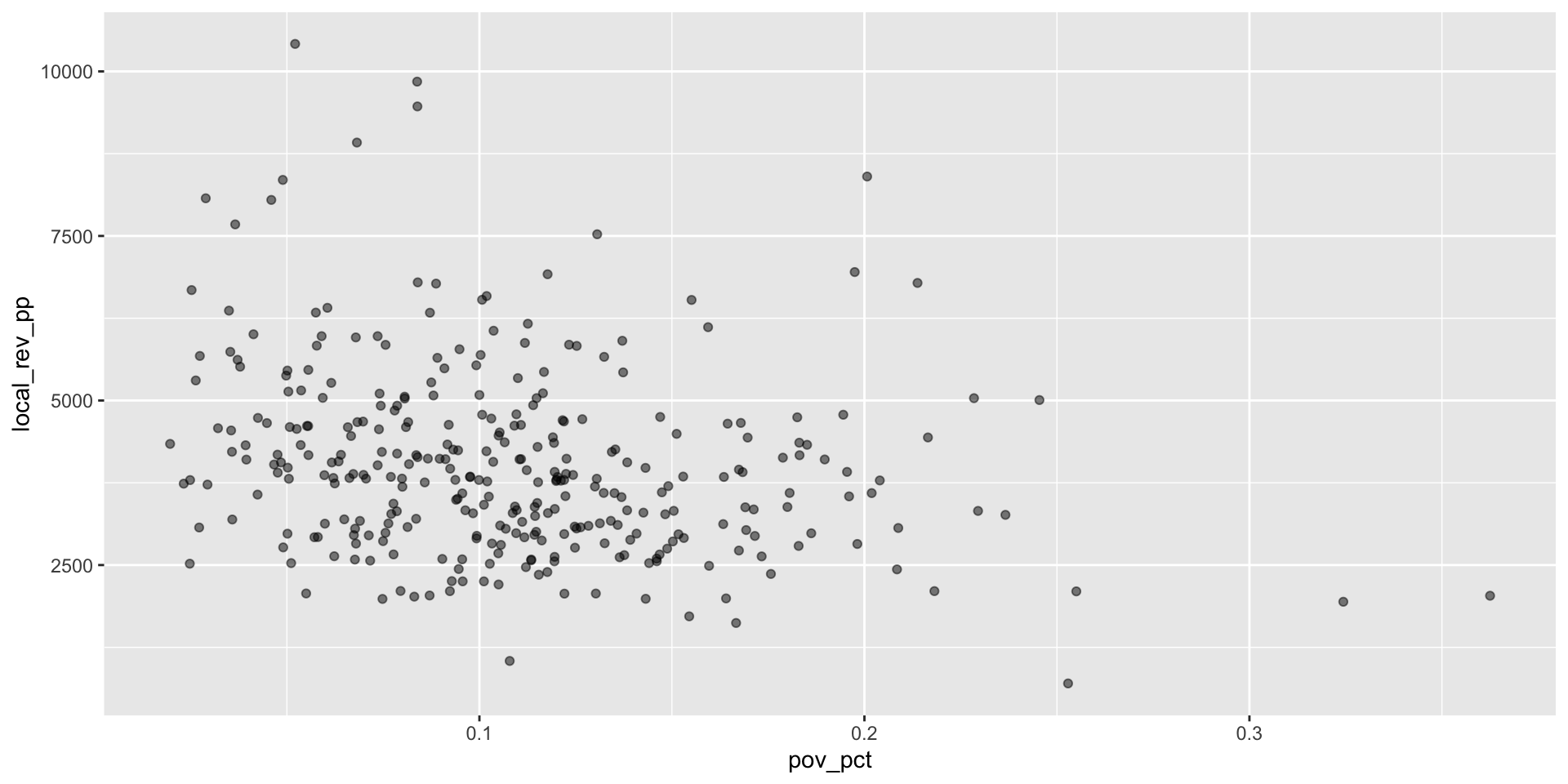
Step 3: Clean up formatting of chart elements (3/5)
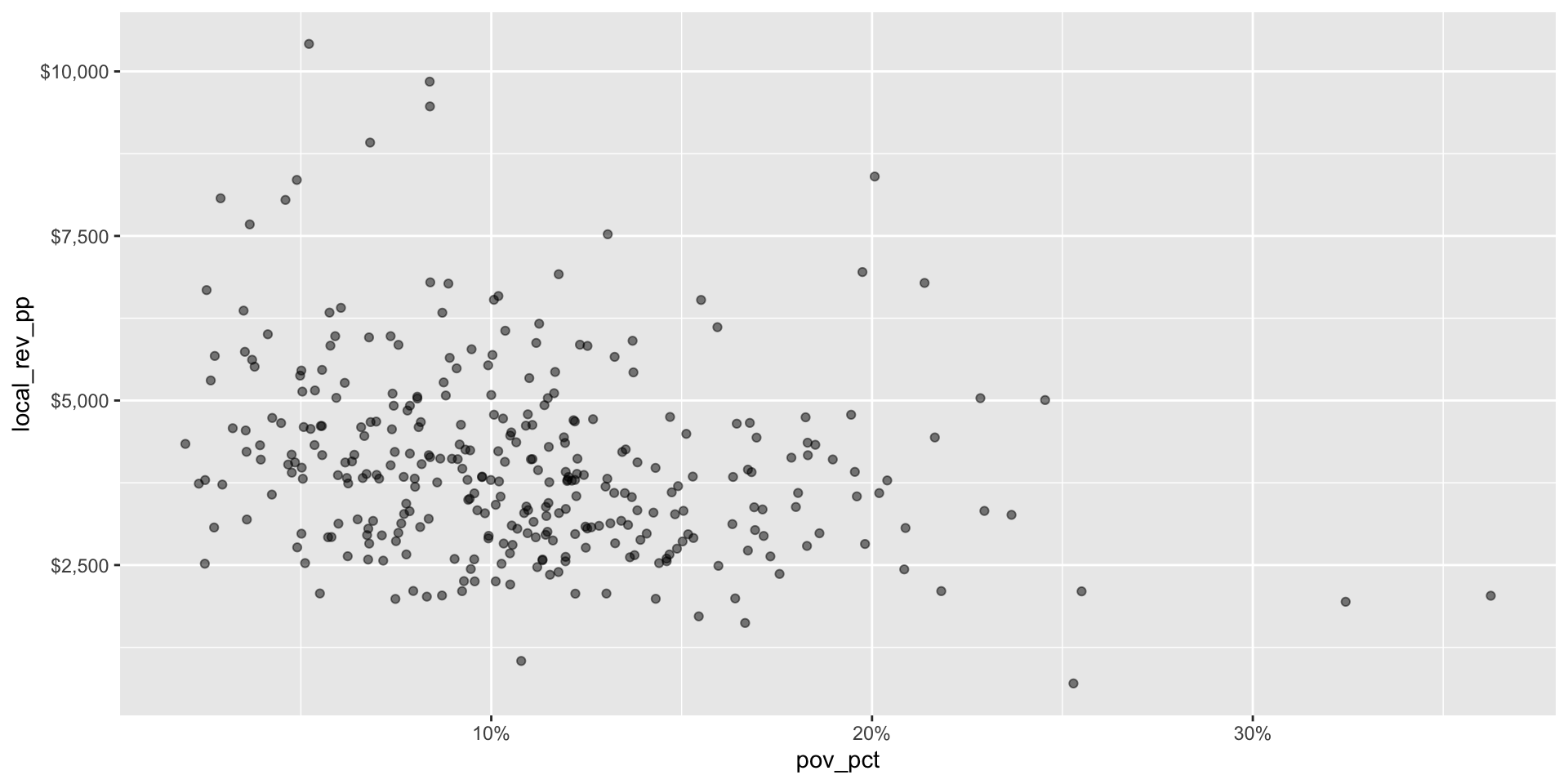
Step 3: Clean up formatting of chart elements (4/5)
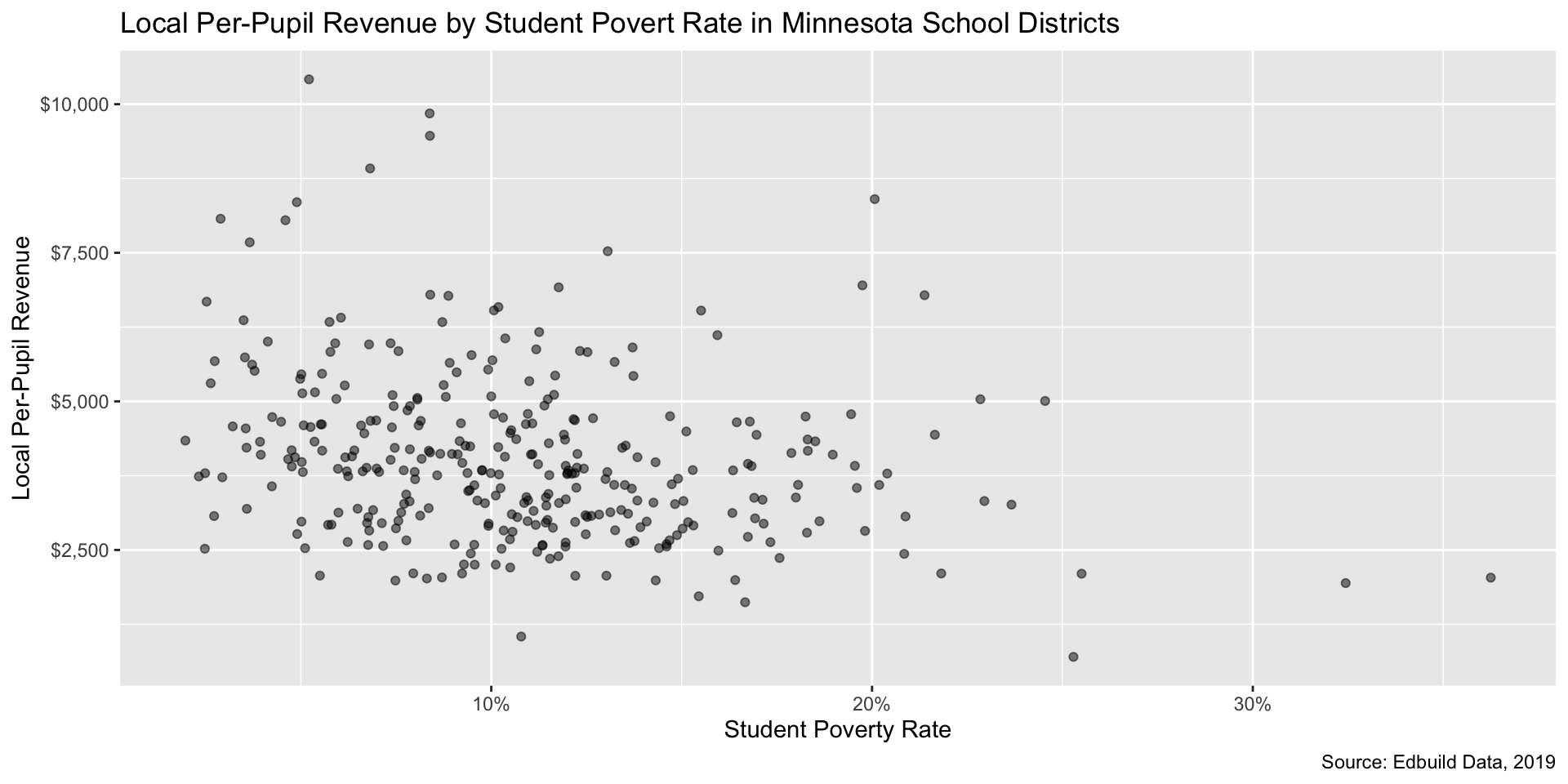
Step 3: Clean up formatting of chart elements (5/5)
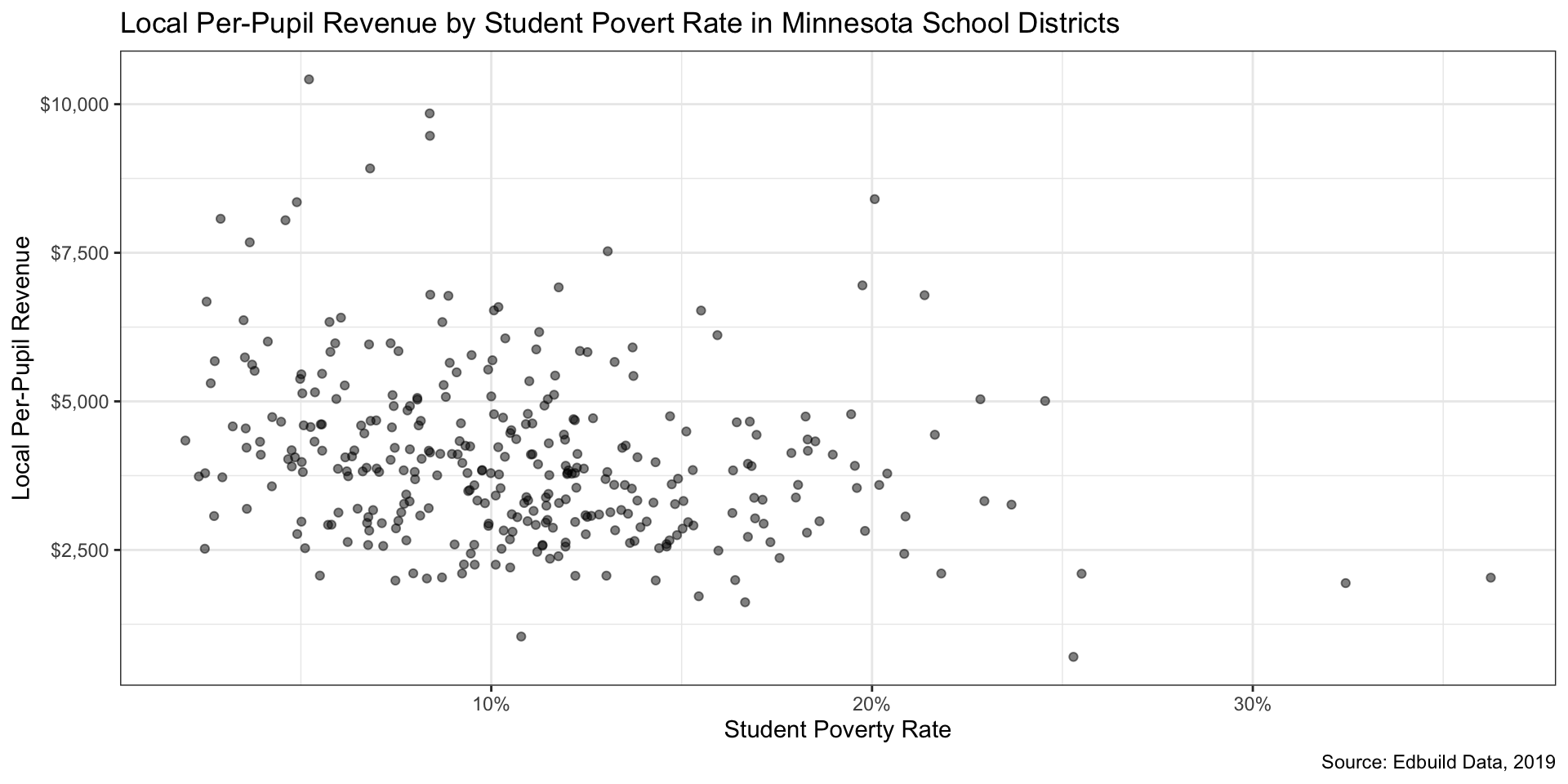
Step 4: Add a new layer of data
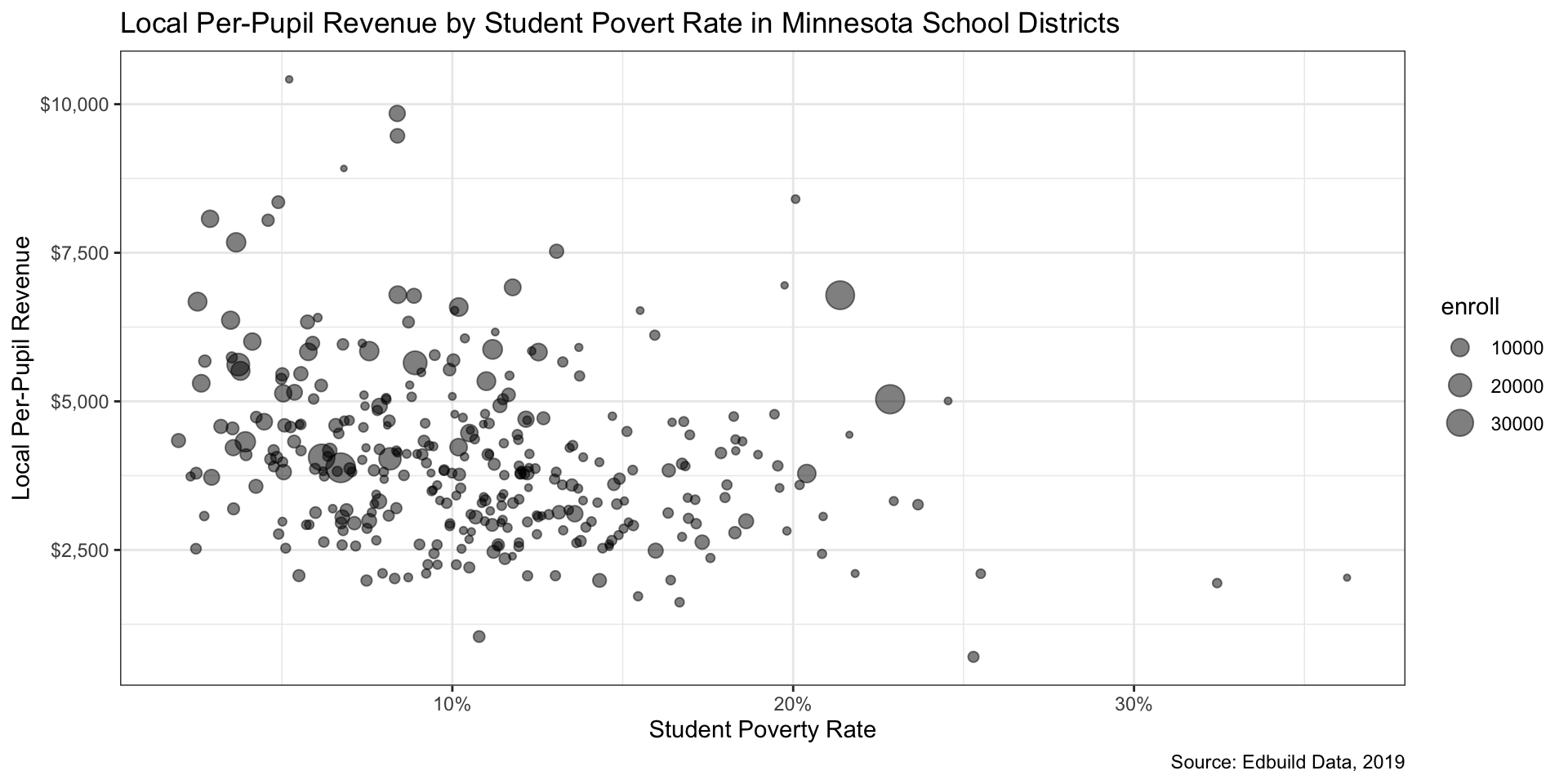
Step 5: Tidy up formatting (1/2)
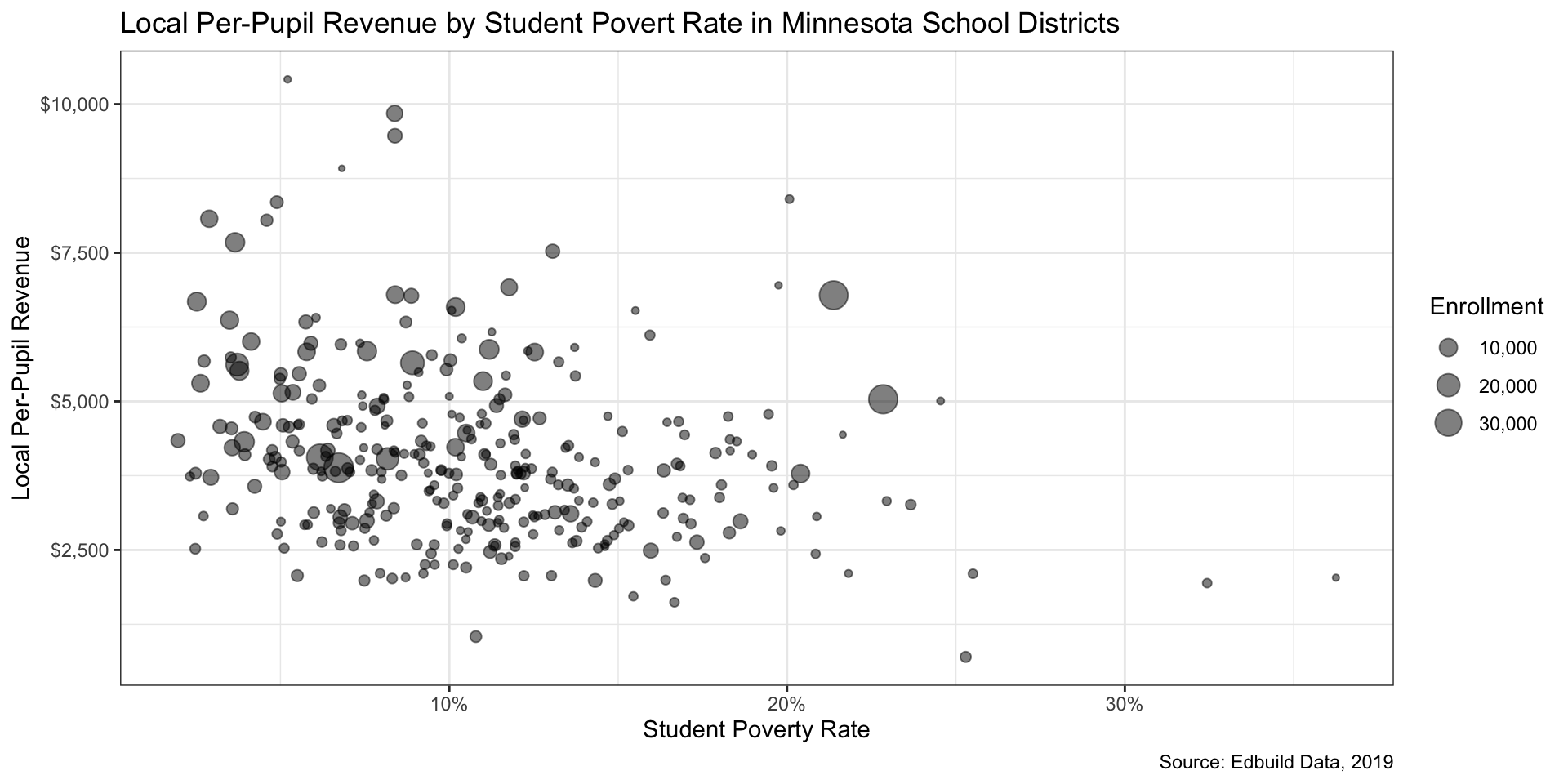
Step 5: Tidy up formatting (2/2)
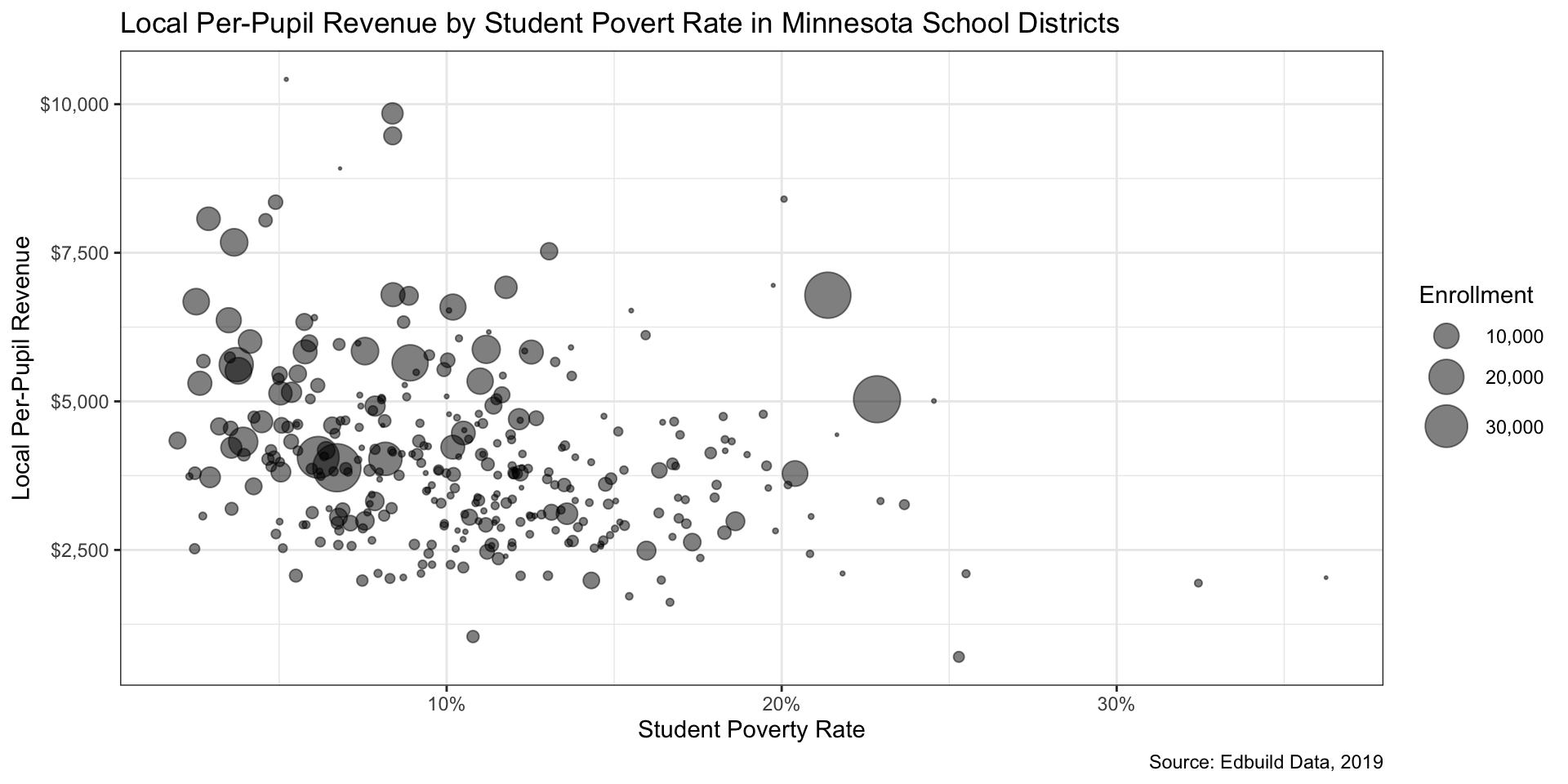
Step 6: Repeat steps 4-5 as needed (1/5)
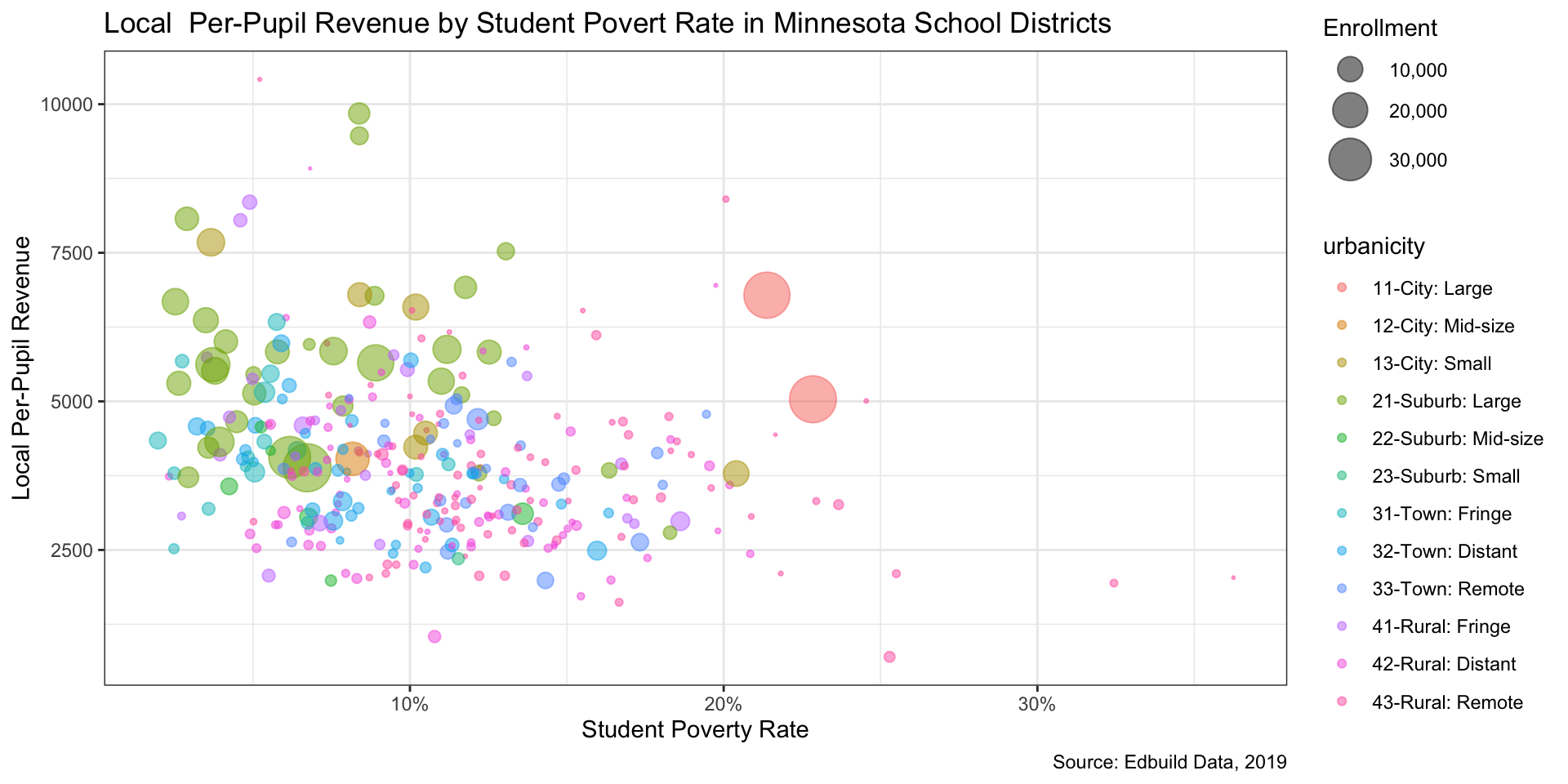
Step 6: Repeat steps 4-5 as needed (2/5)
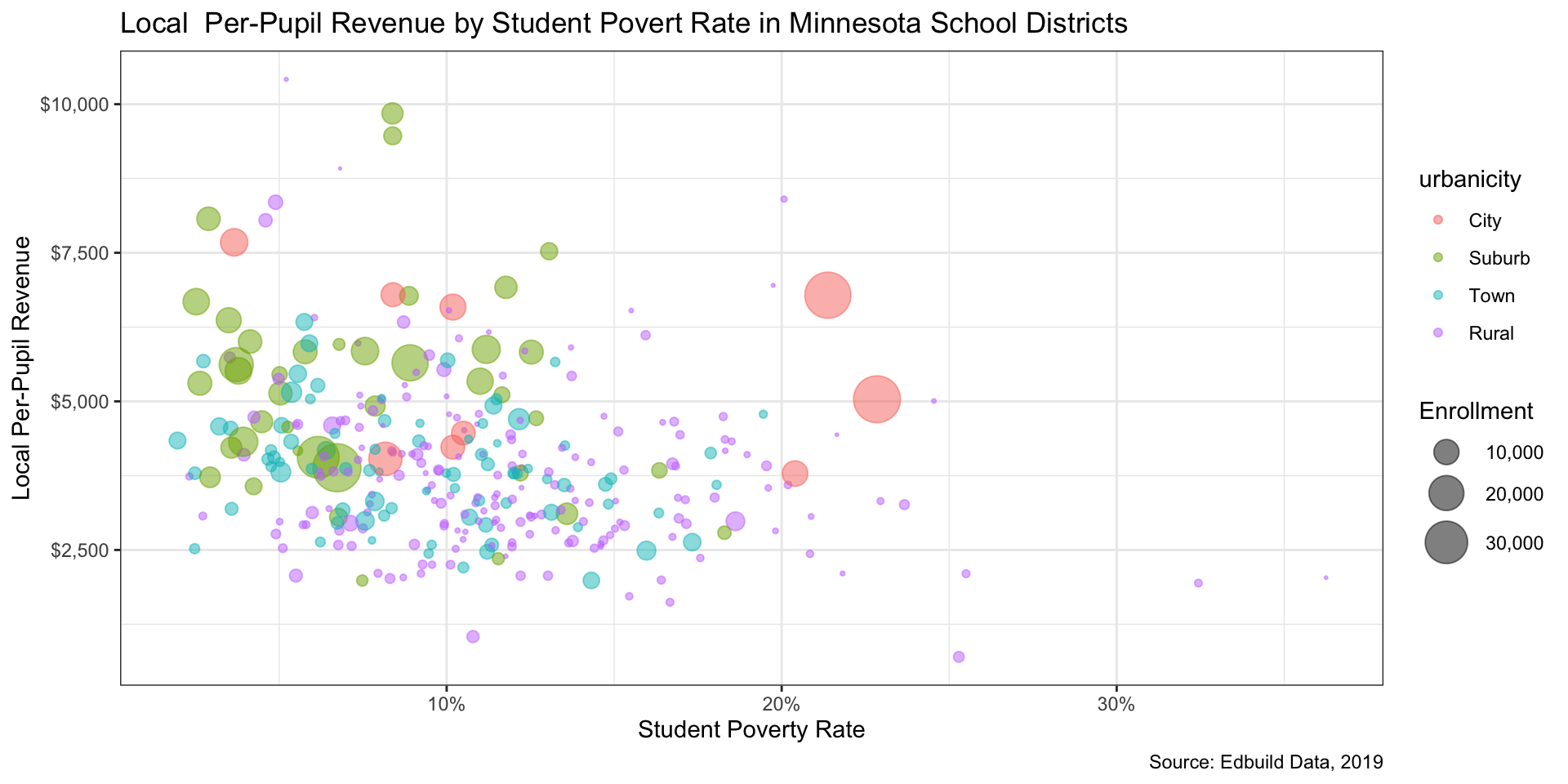
Step 6: Repeat steps 4-5 as needed (3/5)
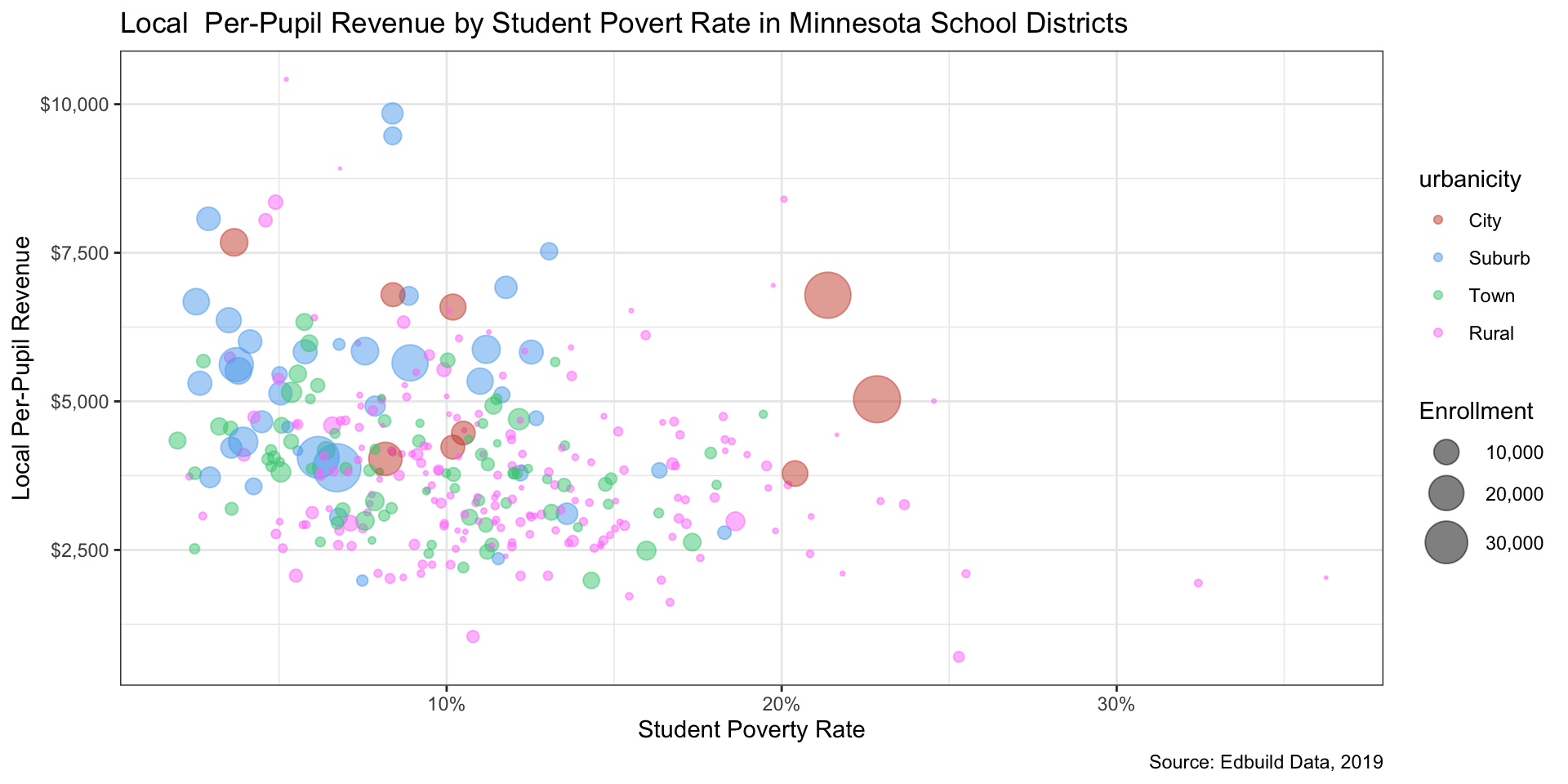
Step 6: Repeat steps 4-5 as needed (4/5)
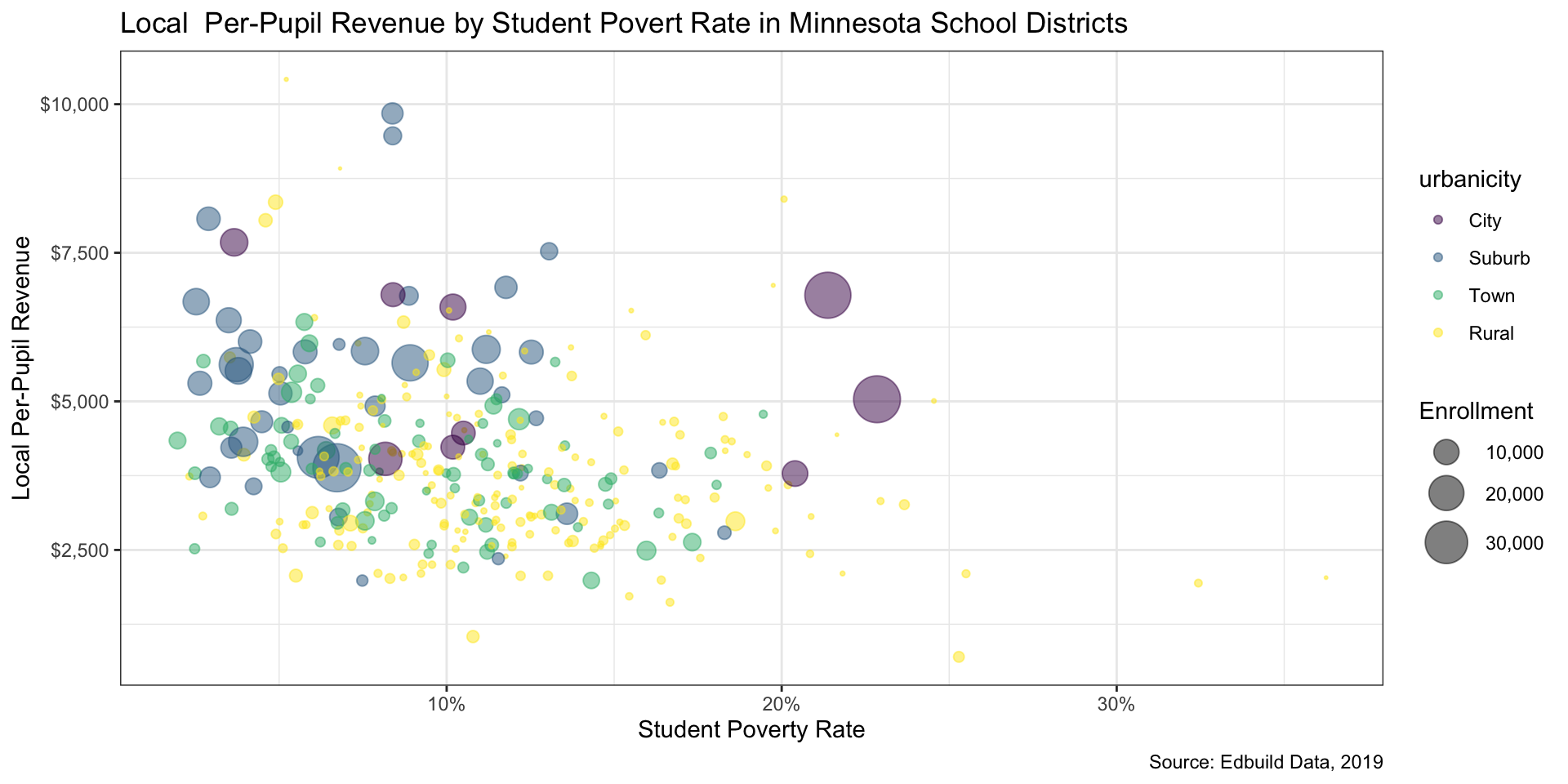
Step 6: Repeat steps 4-5 as needed (5/5)
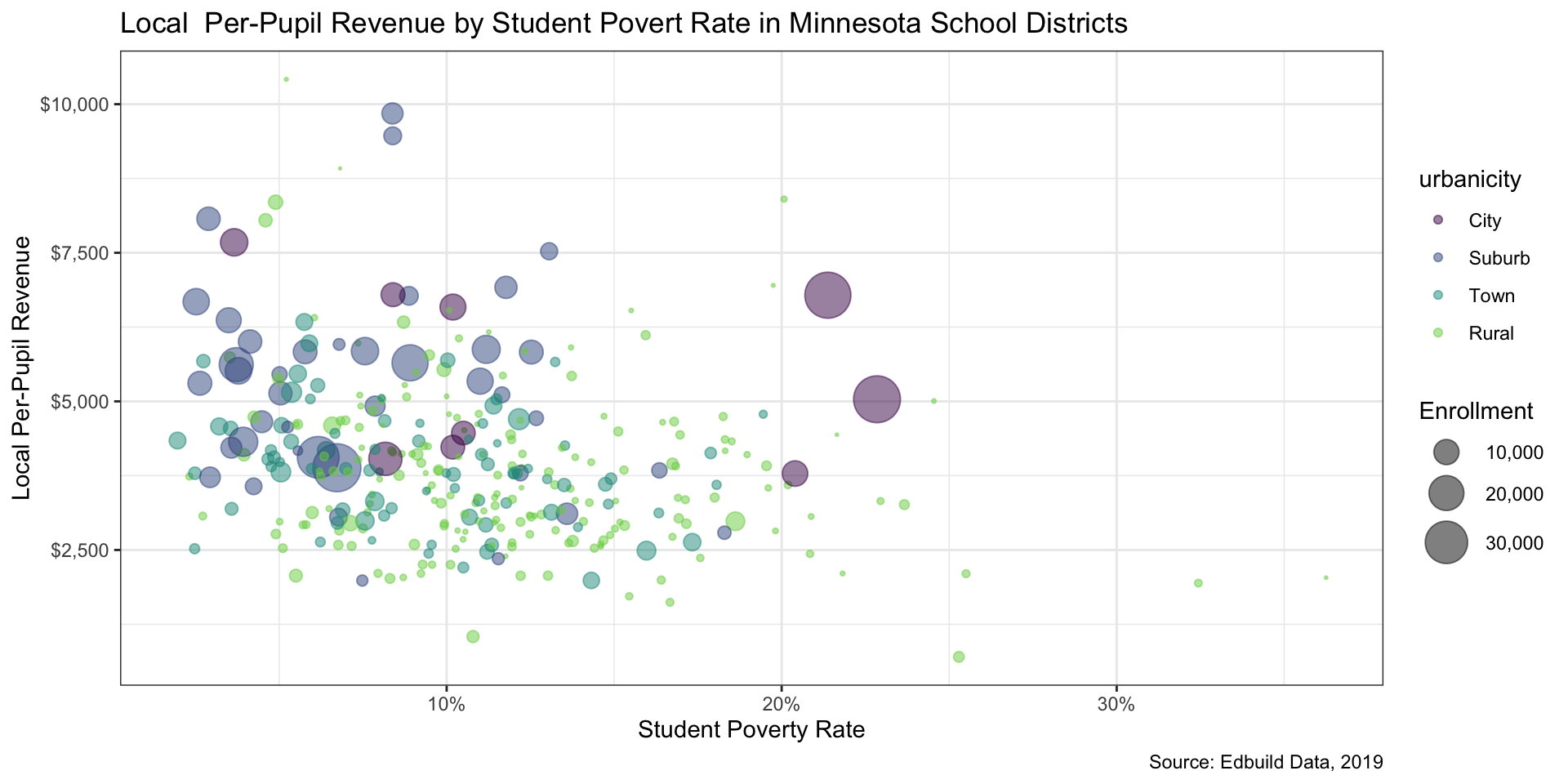
Step 7: Replace a layer of data
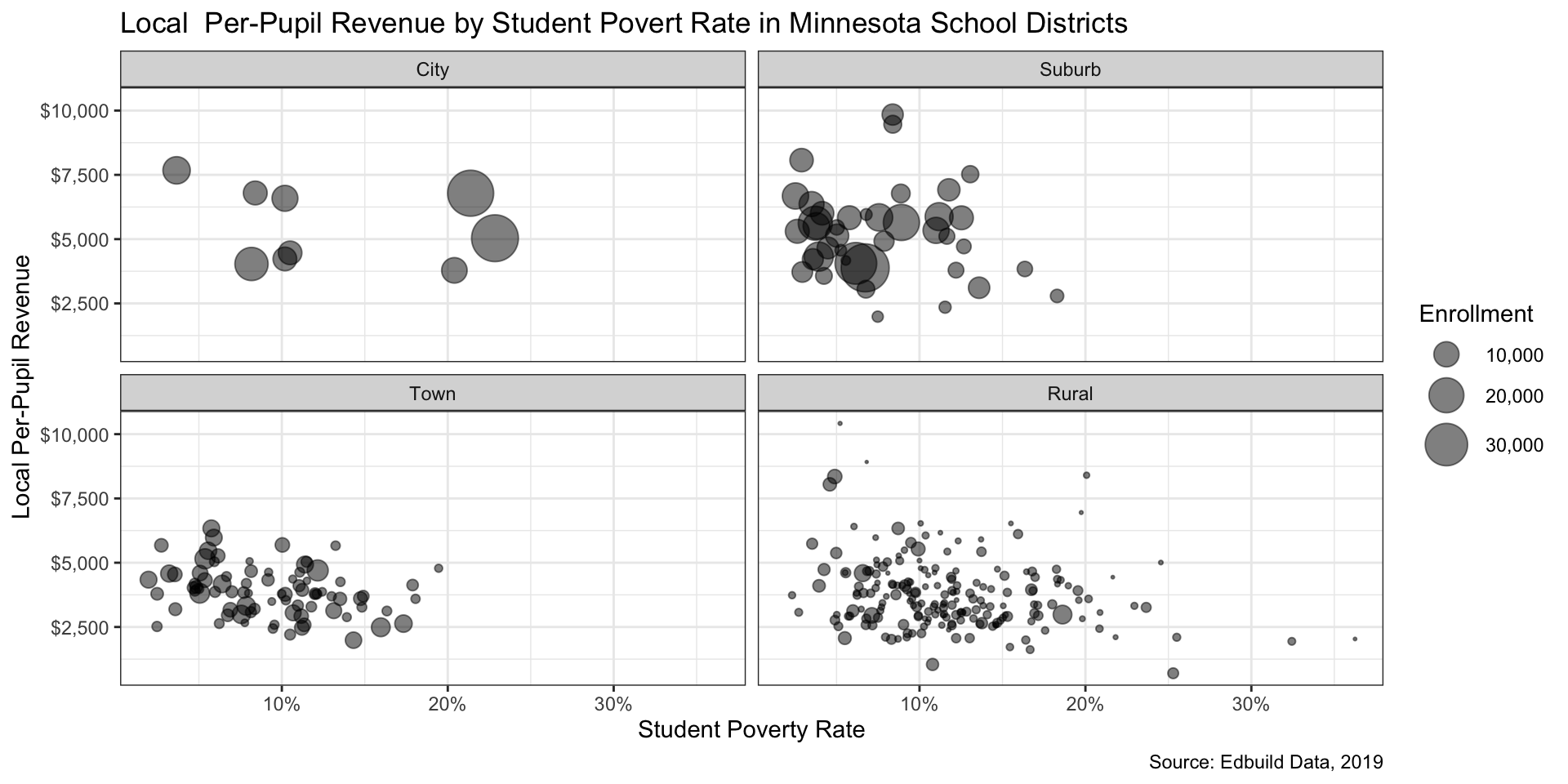
Create histograms (1/3)
Use a histogram to visualize the distribution of median property values across states.
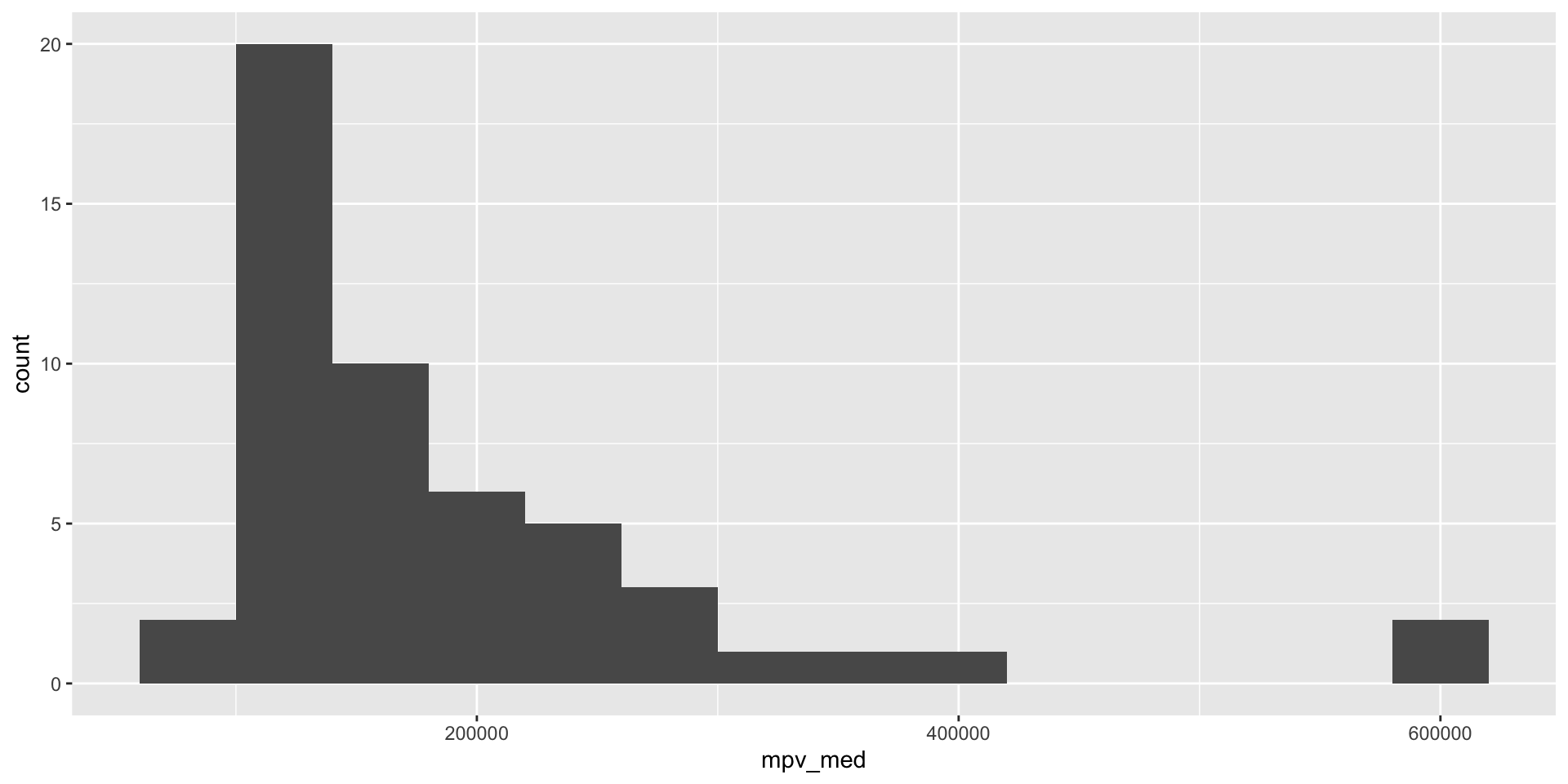
Create histograms (2/3)
Use a histogram to visualize the distribution of median household income across states.
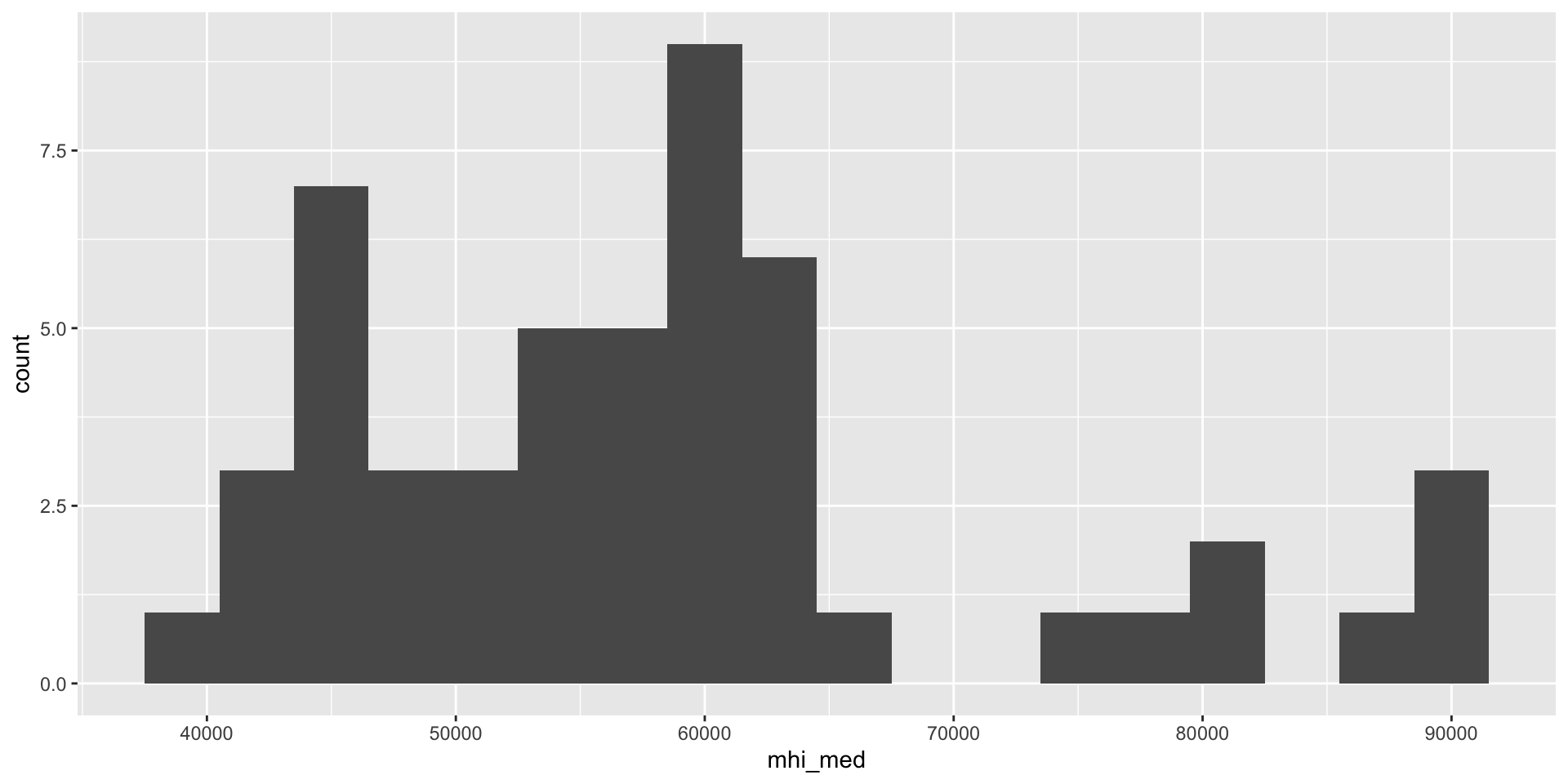
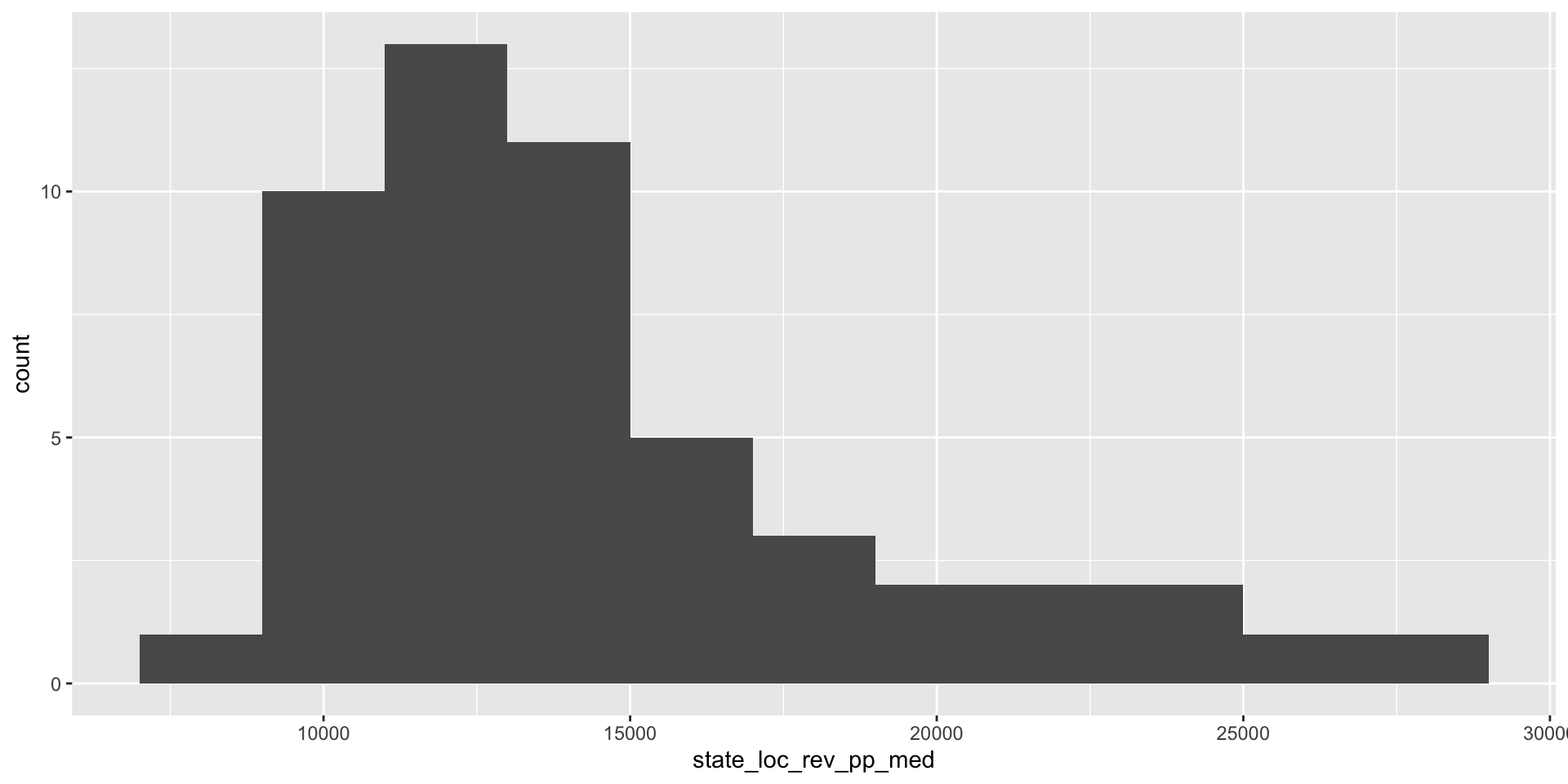
Create histograms (3/3)
Use a histogram to visualize the distribution of state and local per-pupil funding across states.
This week’s assignment
Reading assignment
Coding task
Use edbuildr data and tidyverse functions to:
Create a dataframe that includes
edbuilderdata from your statePlot histograms shows the distributions of property wealth, income, and per-pupil revenue across school districts
Develop two scatterplots that illustrate important relationships in your state’s school finance landscape by working within these options:
X-axis variable options: median household income (
MHI), median property value (MPV), and student poverty rate (StPovRate) as your x-axis variablesY-axis variable options: state per-pupil revenue (
SRPP), local per-pupil revenue (LRPP), and combined state and local per-pupil revenue (SLRPP)Size variable: Enrollment (
ENROLL)Color variables: Urbanicity (
dUrbanicity), median household income (MHI), median property value (MPV), and student poverty rate (StPovRate)Use the formatting techniques covered in class to create nice axis and legend labels and add titles and captions to your plots.
