# A tibble: 3 × 4
state sy20_rev sy21_rev sy22_rev
<chr> <dbl> <dbl> <dbl>
1 AL 2023902 2304983 3930833
2 AK 230993 233466 283948
3 AZ 203492 390282 409828Data cleaning and processing in R
2023-06-27
The principles of “tidy data” provide a helpful vision of what good, clean data should look like
Tidy data follows three rules:
- Each column is a variable
- Each row is an observation
- Each cell is a value
Building tidy datasets will:
• Bring consistency to your data across scripts/projects
• Make it easier to work with functions in the `tidyverse`, which is built to work will with “tidy” data

pivot_longer() is useful when a variable is embedded across several column names
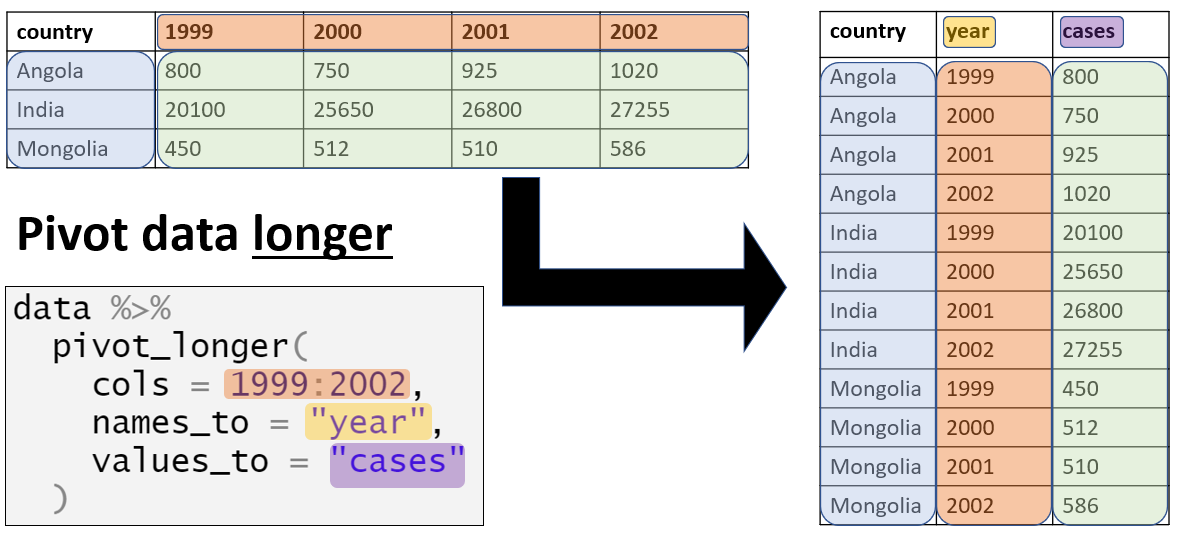
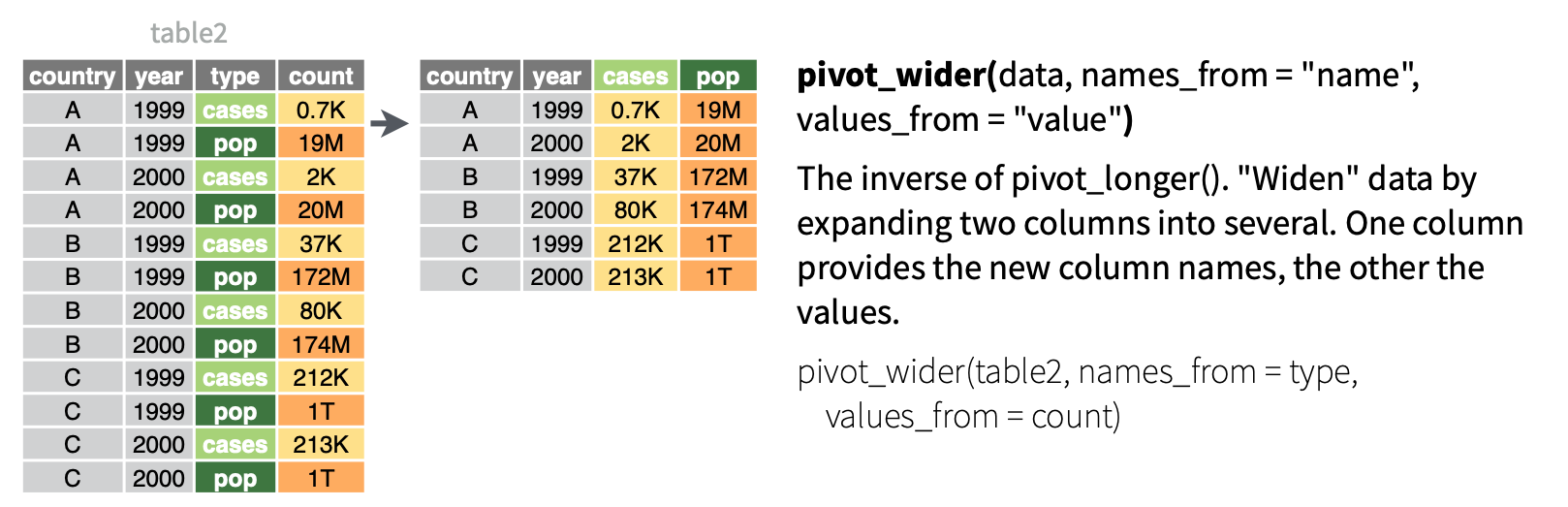
If your data includes data from a single observation spread across multiple rows, use pivot_wider()
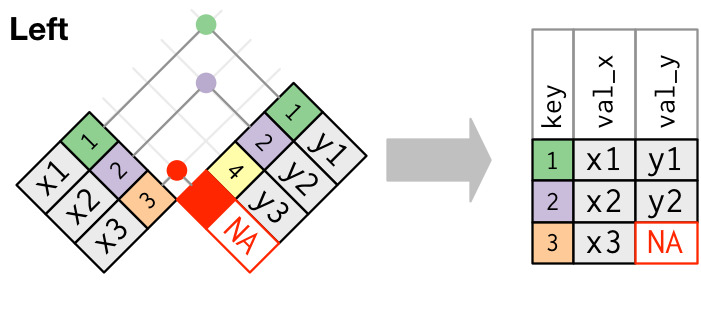
Using left_join() to merge datasets will help preserve your data
Once you have dataframes that share a common ID column, start with your most reliable set of data (typically student count data like ADM or enrollment) and use
left_join()to attach additional data to that table.This approach will preserve your original data, keeping the number of rows (e.g. districts or schools) consistent as you use
left_join()to add data by adding more columns.When a record in the “left” dataframe does not have a match in the “right” dataframe,
left_join()will impute a value ofNAfor all such instances.
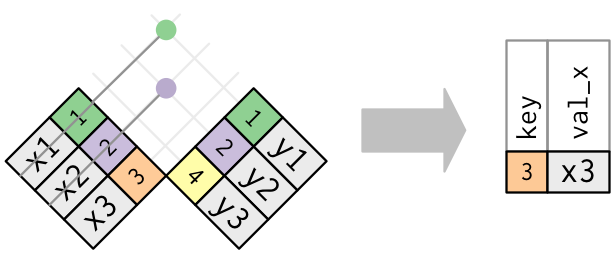
As you merge dataframes, be sure to use anti_join() to examine missing data
Using the anti_join() function from the dplyr package in R returns all rows in one data frame that do not have matching values in another data frame. Using anti_join() allows you to explore the incongruities in your data.
The tidycensus package can provide data at the school district level that may be helpful for school finance analysis
The Census Bureau collects a lot of information that is reported at the school district level. This includes information on topics that are relevant to school finance, like housing.
The tidycensus R package makes it easy to access, explore, and analyze Census Bureau data.
Use install.packages("tidycensus") to download the package in RStudio.
![]()
To get started, you’ll need to sign up for an API key with the Census Bureau

This week’s assignment
Reading assignment
Coding task
Clean your state’s district data and make sure that you have all of the data you need to model your state’s funding formula and the potential policy changes you want to make. This may require joining dataframes, pivot_longer(), pivot_wider() and/or using mutate() to merge, reshape, and tidy data from your state.
Ultimately, you’ll want to produce a single dataframe where:
- Each row represents a single LEA (traditional district or charter school)
- Each column represents a single variable
- All of the data elements that go into your current formula are present in the dataframe.
If you need to join more than two dataframes, just start with joining two dataframes for this assingment. We can work on building the full dataset you’ll need to model your formula over the coming weeks.
To get started, a template R script is included: scripts/dist_clean.R – please use that file to load, clean, and save your tidy data.
As always, once you’ve completed the assignment, be sure to commit and push to GitHub!
