Reproducible data analysis in R
2023-07-11
You can (and should) start your projects by creating a new repo on your GitHub account
Remember: After you’ve created a project, use a consistent folder structure to keep your analysis organized
Building a consistent file structure in your projects will help you (and others!) easily navigate your code.
Minimally, you will want to have a separate folder for:
datascriptsfigures

Another layer of organization: Separate your raw and processed data!
- Use sub-folders within your
/datafolder to keep your raw data files separated from any processed data files you produce during your analysis. - This creates additional procedural barrier to accidentally over-writing your raw data.
- Use the
/processeddata folder for exporting clean data or results of your analysis, like summary tables.
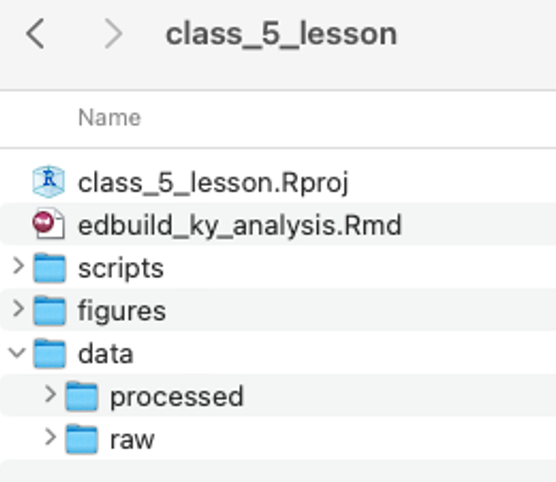
R Markdown is a special file type that allows you to combine code with plain text to create reports
YAML Header: Controls certain output settings that apply to the entire document.
Code Chunk: Includes code to run, and code-related options.
Body Text: For communicating results and findings to the targeted audience.
Code to Generate a Table: Outputs a table with minimal formatting like you would see in the console.
Section Header: Specified with
##.Code to Generate a Plot: Outputs a plot. Here, the code used to generate the plot will not be included because the parameter
echo=FALSEis specified.
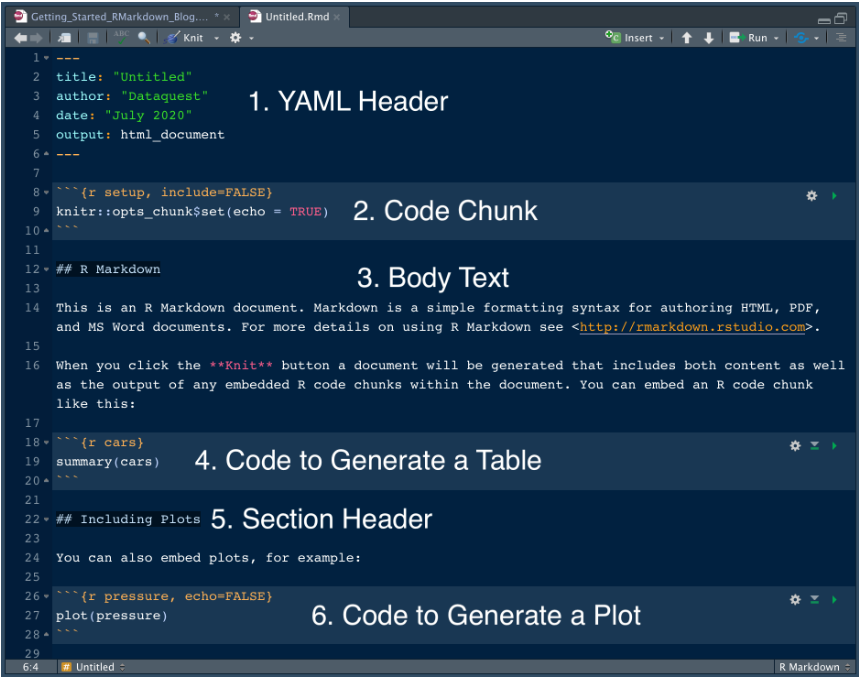
R Markdown combines “chunks” of R code with blocks of Markdown-formatted text
R code chunks in R Markdown are contained within a pair of triple backticks that include a curly brace that indicates the section contains r code:
```{r}
<code goes here>
```
Markdown is a *really* easy way to format text. For more, visit Markdown Guide).
For more on using R Markdown documents, check out RStudio’s resources here.

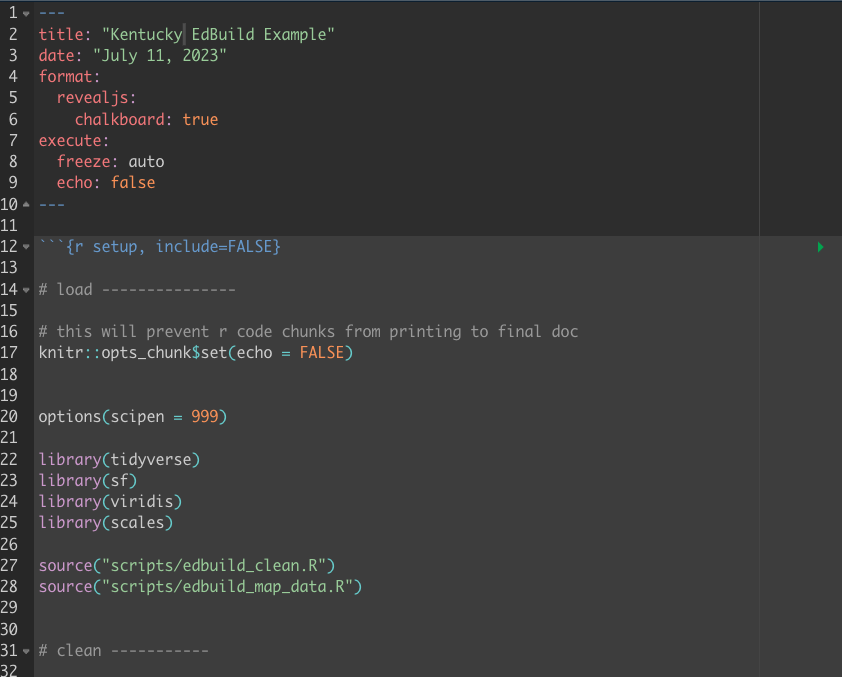
LIVE CODING EXAMPLE: Kentucky EdBuild Data Analysis
Quarto is a multi-language, next generation version of R Markdown from RStudio
- Like R Markdown, Quarto is free and open source
- Quarto also uses Knitr to execute R code, so it can render most existing Rmd files without modification
- Use a single source document to target multiple formats (HTML, PDF, Word, etc.)
- It’s language-agnostic. It can render documents that contain code written in R, Python, Julia, or Observable.
- Check out the gallery of Quarto examples
How to use Quarto: Rendering
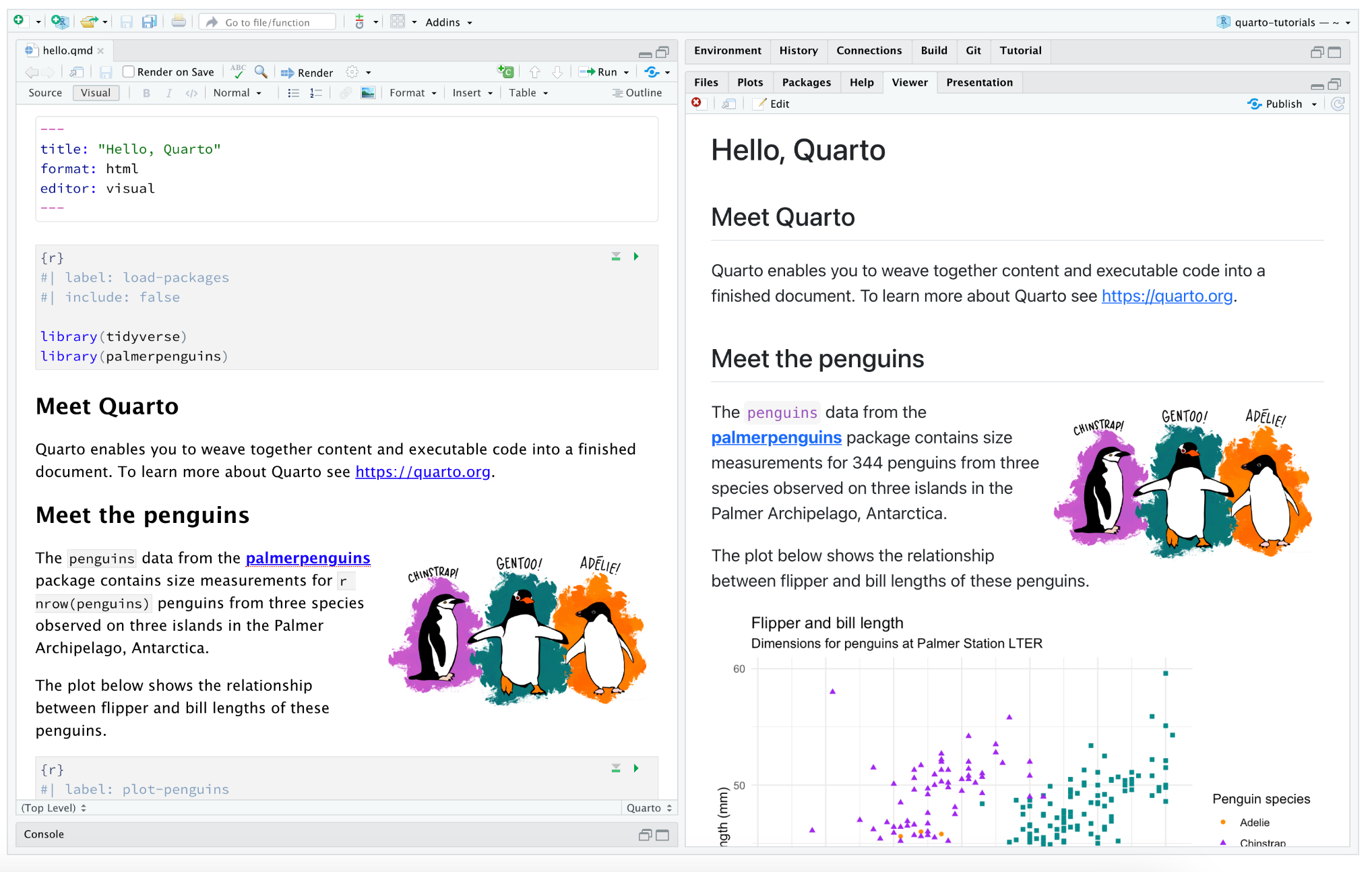
Use the Render button to render the file and preview the output with a single click or keyboard shortcut (⇧⌘K)
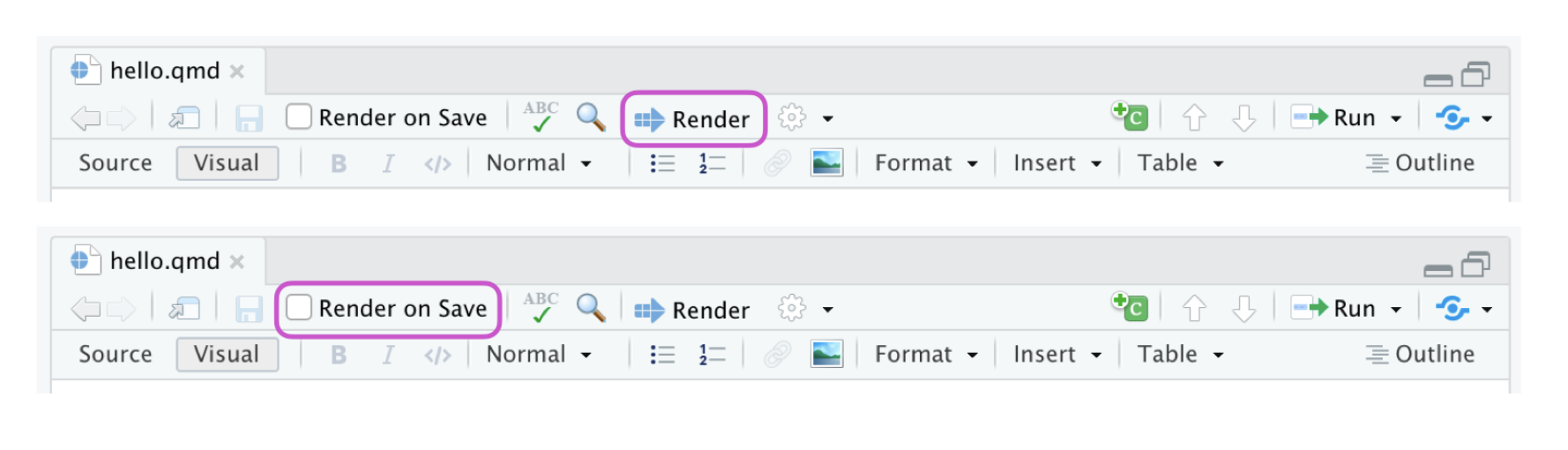
You can also automatically render whenever you save. To do that you check the Render on Save option on the editor toolbar. The preview will update whenever you re-render the document. Side-by-side preview works for both HTML and PDF outputs.
When rendering, Quarto generates a new file that contains selected text, code, and results from the .qmd file. The new file can be an HTML, PDF, MS Word document, presentation, website, book, interactive document, or other format.
How to use Quarto: Authoring
LIVE CODING EXAMPLE: Kentucky EdBuild Data Analysis
This week’s homework assignment
Reading assignment
Coding task
- Continue working on your
week04assignment! - If you’ve completed a join of your first two datasets, add in the rest of the data you’ll need to model your state’s current funding formula
- Two blocks of office hours will be available this week on Thursday and Friday to help with any data joining and/or cleaning challenges
Finance contact
- Please share the contact information for your organization’s finance/operations lead by Friday, July 14. We will be contacting them next week regarding the grant funding we have available.
